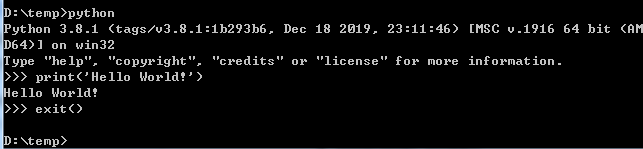
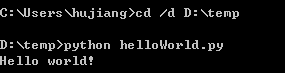
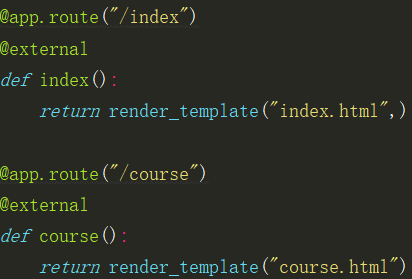
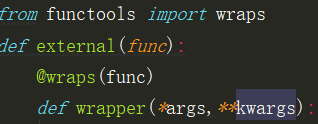
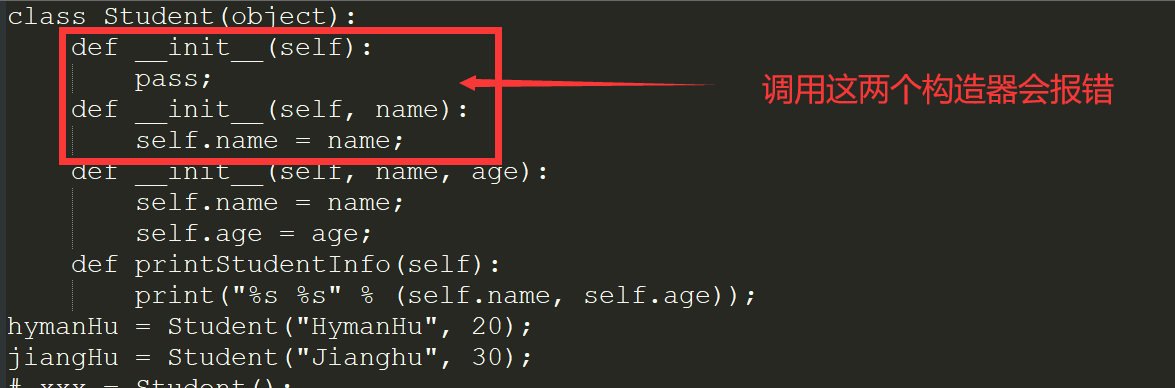
def __init__(self, columnName, columnType):
self.columnName = columnName;
self.columnType = columnType;
return "<%s : %s>" % (self.__class__.__name__, self.columnName);
class StringField(Field):
def __init__(self, columnName):
super(StringField, self).__init__(columnName, "varchar(100)");
class IntegerField(Field):
def __init__(self, columnName):
super(IntegerField, self).__init__(columnName, "bigint");
field = Field("userId", int);class ModelMetaclass(type):
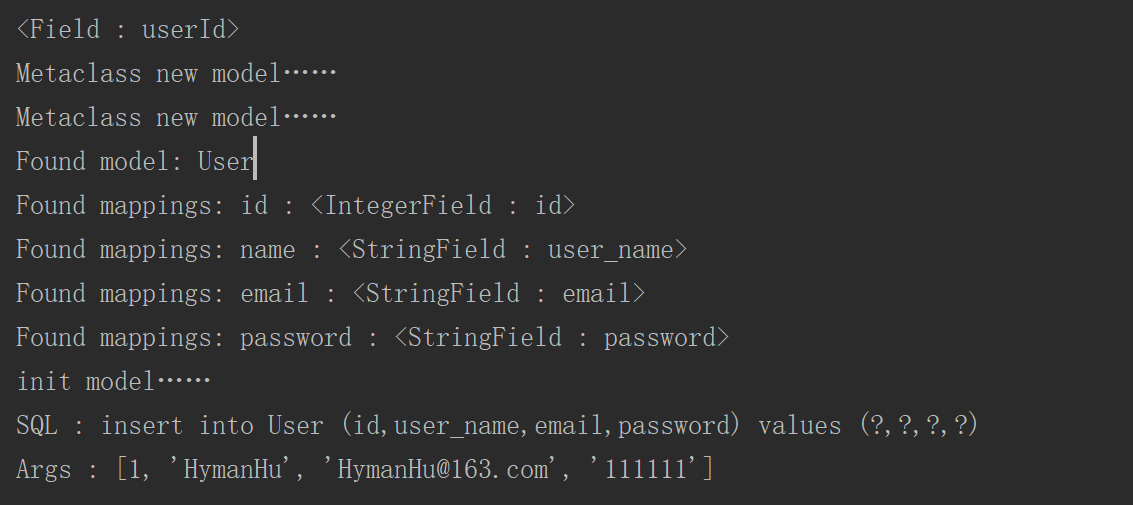
思路:Model是dict子类,每个key对应一个列对象
1、将不同的Model子类中classAttrs(属性和方法)的属性过滤出来,装载到mappings里面
2、返回Model对应的表名,在此默认Model子类类名
def __new__(typ, className, parentClassList, classAttrs):
print("Metaclass new model……"); return type.__new__(typ, className, parentClassList, classAttrs);
print("Found model: %s" % className); for key, value in classAttrs.items():
if isinstance(value, Field):
print("Found mappings: %s : %s" % (key, value)); for key in mappings.keys():
classAttrs["__mappings__"] = mappings;
classAttrs["__table__"] = className;
return type.__new__(typ, className, parentClassList, classAttrs);
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw);
def __getattr__(self, key):
raise AttributeError("Model object has no attribute %s" % key); def __setattr__(self, key, value):
1、遍历mappings,得到对应的列对象,build sql语句
2、调用getattr函数,将每列的值装载到args这个list中
for key, value in self.__mappings__.items():
fields.append(value.columnName);
args.append(getattr(self, key, None));
sql = "insert into %s (%s) values (%s)" % (self.__table__, ",".join(fields), ",".join(params));
print("Args : %s" % str(args)); name = StringField("user_name"); email = StringField("email"); password = StringField("password");user = User(id = 1, name = "HymanHu", email = "HymanHu@163.com", password = "111111");