- 你其实在银行有 1000w 存款,只不过你忘记了密码,每输入一次需要两元,一旦正确,钱就是你的,不着急,不放弃,心若在,梦就在……
- Python 爬虫 + 数据处理 + 时间预测 + Web 展示。
环境依赖
系统环境
- Windows + Python 3.8.16
- IDE:Pycharm
- DB:Mysql 8.x
第三方依赖
- pip install mysql-connector:MySQL 连接器;
- pip install sqlalchemy:数据库 ORM 框架 sqlalchemy;
- pip install requests:爬虫第三方库;
- pip install bs4:数据解析库;
- pip install numpy:N 维数组处理库;
- pip install pandas:面板数据分析库;
- pip install matplotlib:绘制图表;
- pip install pyecharts:绘图;
- pip install statsmodels:数据统计预测库;
- pip install wheel:Python 的一种生成包格式文件,像一种特定的 zip 文件,以 .whl 后缀;
- pip install tensorflow:机器学习框架;
- pip install keras:神经网络 API;
实现
需求分析
功能需求
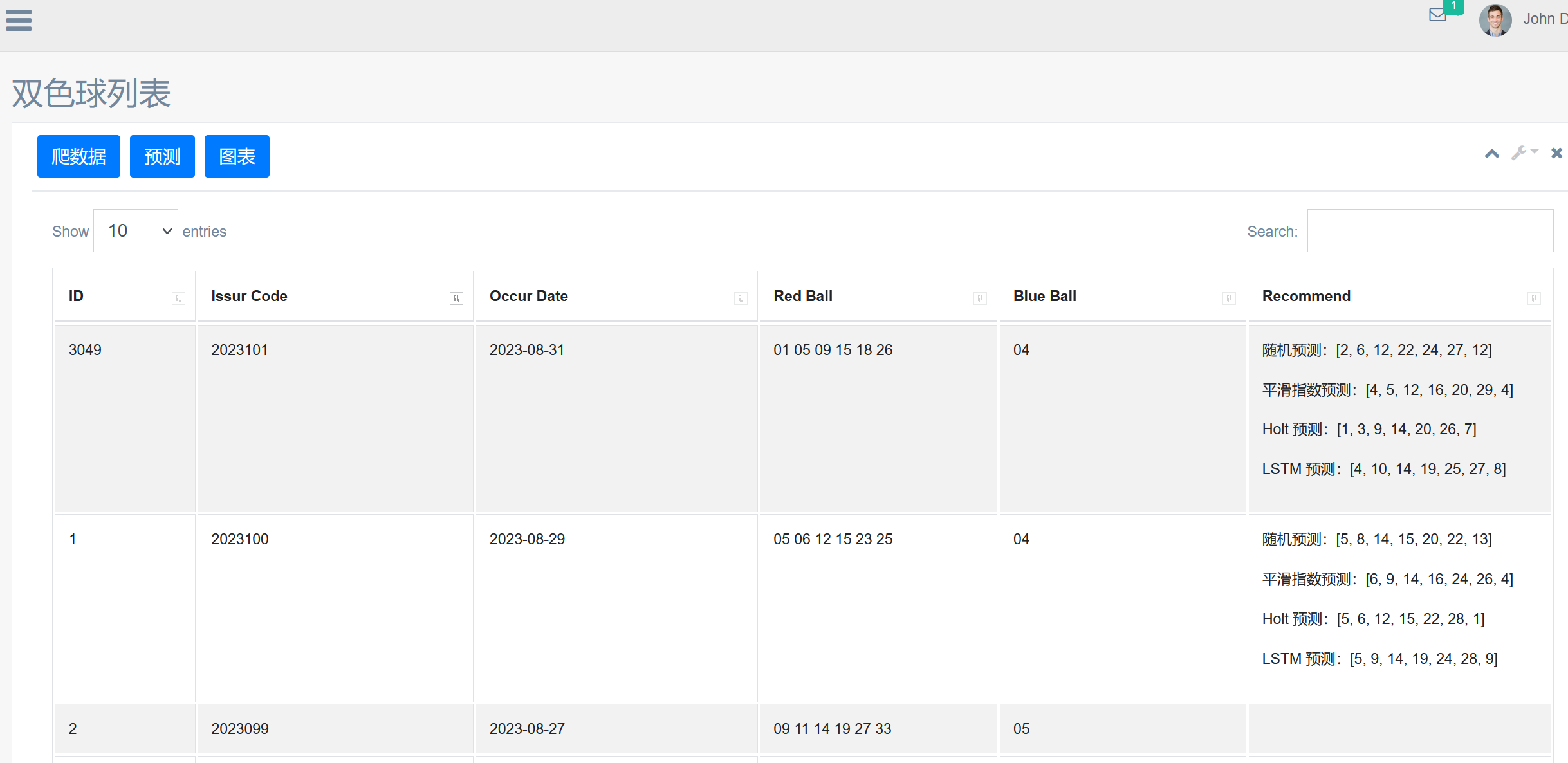
- 使用 Python 爬取双色球历史数据 http://kaijiang.zhcw.com/zhcw/html/ssq/list.html, 并将结果存入数据库中;
- 读取数据,构造 DateFrame 结构,并进行拆分合并;
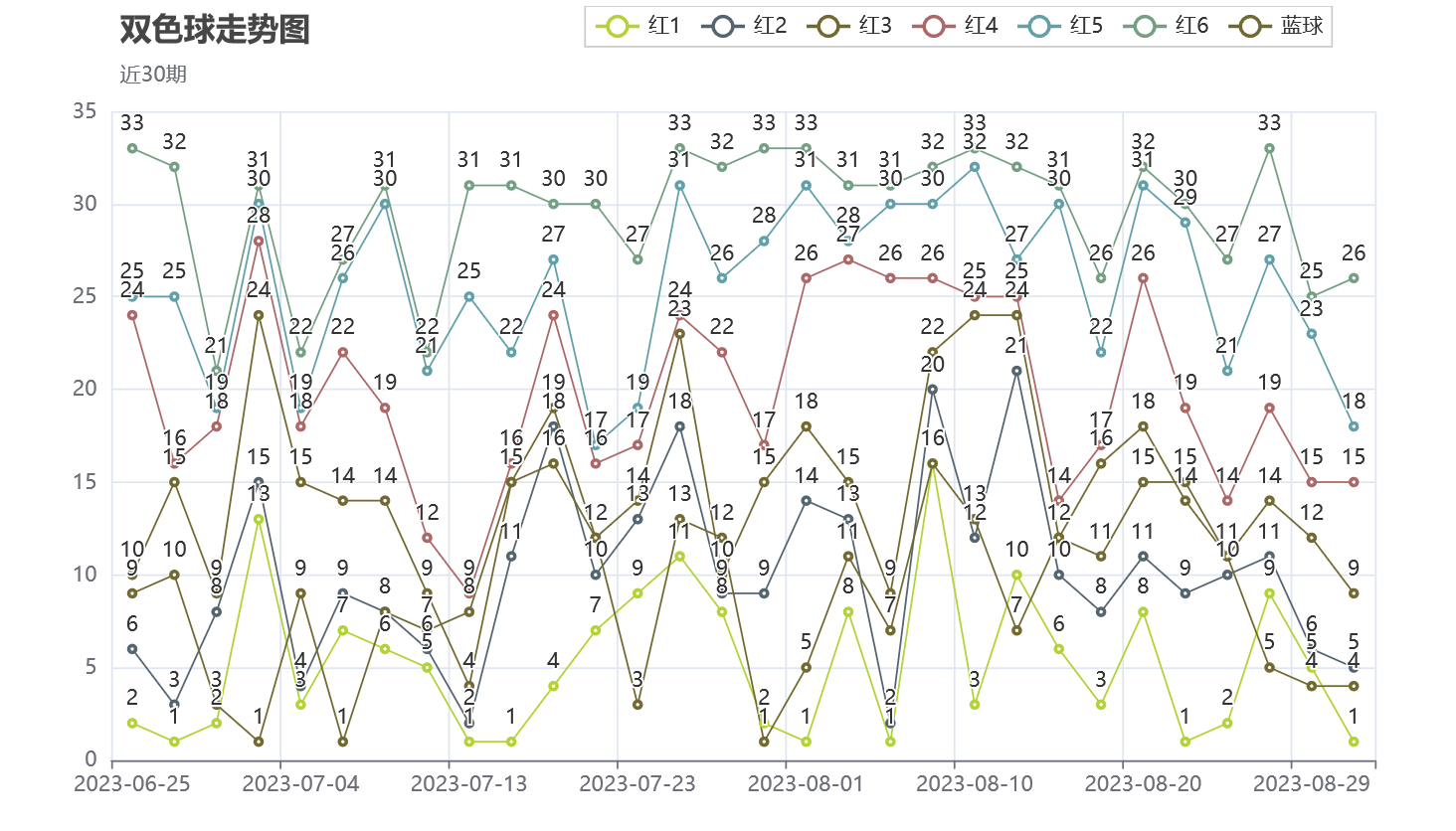
- 绘制最近 30 期数据走势图;
- 采用多种方法对下期数据进行预测,并将预测结果存入数据库;
- 搭建 Web 项目,展示数据列表,并提供按钮操作爬虫、预测和走势图展示。
项目设计
编码规范
- Python
- 常规:全小写、下划线;
- 类:大驼峰;
- 常量:全大写、下划线;
- DB
- 全小写、下划线;
- Java
- 常规:驼峰法
- JavaScript
- 常规:驼峰法
原型设计
- double_color_ball.sql
- 11
SET NAMES utf8mb4;2SET FOREIGN_KEY_CHECKS = 0;34-- ----------------------------5-- Table structure for double_color_ball6-- ----------------------------7DROP TABLE IF EXISTS `double_color_ball`;8CREATE TABLE `double_color_ball` (9`id` int(0) NOT NULL AUTO_INCREMENT,10`issur_code` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,11`occur_date` date NULL DEFAULT NULL,12`red_ball` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,13`blue_ball` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,14`recommend` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,15`create_date` datetime(0) NULL DEFAULT NULL,16`update_date` datetime(0) NULL DEFAULT NULL,17PRIMARY KEY (`id`) USING BTREE18) ENGINE = InnoDB AUTO_INCREMENT = 3049 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;1920SET FOREIGN_KEY_CHECKS = 1;21 - 2
系统架构
- Wish_Spider
- 爬虫:requests + bs4;
- 数据存储:Mysql + PyMysql + Sqlalchemy;
- 数据处理:Numpy + Pandas;
- 数据展示:Pyecharts;
- 数据预测:随机预测、平滑指数预测、Holt 预测、LSTM 神经网络预测。
- Wish_Web
- Django + Jquery + Bootstrap。
项目开发
Wish_Spider
Utils
- pymysql_util.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "HymanHu";45'''6Pymysql 工具类7'''89import pymysql;1011# 获取链接对象、游标对象12def get_connection_cursor():13connect = pymysql.connect(host="127.0.0.1", port=3306, database="kg20",14user="root", password="root", charset="utf8mb4");15# 从链接对象中获取游标对象16cursor = connect.cursor();17return connect, cursor;1819def execute_edit(cursor, sql):20return cursor.execute(sql);2122def execute_query(cursor, sql):23cursor.execute(sql);24return cursor.fetchall();2526def commit_(connect):27connect.commit();2829def rollback_(connect):30connect.rollback();3132def close_(connect, cursor):33if cursor:34cursor.close();35if connect:36connect.close();3738def execute_edit_(sql):39result = None;40connect, cursor = None, None;41try:42connect, cursor = get_connection_cursor();43result = execute_edit(cursor, sql);44commit_(connect);45except BaseException as e:46print(e);47rollback_(connect);48finally:49close_(connect, cursor);5051return result;5253def execute_query_(sql):54result = None;55connect, cursor = None, None;56try:57connect, cursor = get_connection_cursor();58result = execute_query(cursor, sql);59except BaseException as e:60print(e);61finally:62close_(connect, cursor);6364return result; - 2
- sqlalchemy_util.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "HymanHu";45'''6sqlalchemy util7'''89# 将项目根目录添加到 sys.path,解决 cmd 下执行该模块找不到包的问题10import sys, os;11current_path = os.path.abspath(os.path.dirname(__file__));12separator = "\\" if os.name == "nt" else "/";13project_name = "python_spider" + separator;14root_path = current_path[:current_path.find(project_name) + len(project_name)]; # 获取项目根目录15sys.path.append(root_path);1617from sqlalchemy import Column, String, Text, text, Integer, BigInteger, Float, Date, DateTime, ForeignKey, create_engine, and_, or_;18from sqlalchemy.orm import sessionmaker, relationship;19from sqlalchemy.ext.declarative import declarative_base;2021# 创建对象基类22Base = declarative_base();2324# 初始化数据库引擎25def init_db_engine():26engine = None;27try:28engine = create_engine("mysql+mysqlconnector://root:root@localhost:3306/kg20?auth_plugin=mysql_native_password");29except Exception as e:30print("数据库连接失败,异常:%s" % e);31return engine;3233# 创建数据库表34def init_db():35engine = init_db_engine();36if engine:37Base.metadata.create_all(engine, checkfirst=True);3839# 初始化 DB Session40def init_db_session():41engine = init_db_engine();42if engine:43session = sessionmaker(bind=engine);44return session();45else:46return None;4748# 新增49def insert_(entity, key):50session = init_db_session();51if session:52try:53# select * from coronavirus where date == ?54'''55根据实体 bean 的某个字段作为唯一标识,查询数据库是否已经存在,不存在则插入新的数据56构造 sql(列举): select * from coronavirus where date == ?57'''58results = session.query(type(entity)).filter(59type(entity).__dict__.get(key) == entity.__dict__.get(key)60).all();61if len(results) == 0:62session.add(entity)63session.commit();64except Exception as e:65print(e);66session.rollback();67finally:68session.close();6970# 修改71def update_(entity, key):72d = entity.__dict__;73d.pop("_sa_instance_state");74session = init_db_session();75if session:76try:77session.query(type(entity)).filter(78type(entity).__dict__.get(key) == entity.__dict__.get(key)79).update(d);80session.commit();81except Exception as e:82print(e);83session.rollback();84finally:85session.close();8687# 删除88def delete_(entity, key):89session = init_db_session();90if session:91try:92session.query(type(entity)).filter(93type(entity).__dict__.get(key) == entity.__dict__.get(key)94).delete();95session.commit();96except Exception as e:97print(e);98session.rollback();99finally:100session.close();101102# 查询所有103def get_all(entity):104results = None;105session = init_db_session();106if session:107results = session.query(type(entity)).all();108session.close();109return results;110111# 查询单个112def get_one(entity, key):113result = None;114session = init_db_session();115if session:116result = session.query(type(entity)).filter(117type(entity).__dict__.get(key) == entity.__dict__.get(key)118).first();119session.close();120return result;121122# 原生 sql123def execute_(sql):124results = None;125session = init_db_session();126if session:127if sql.lower().startswith("select"):128'''129- 高版本在执行 sql 时候,需加上 text(sql) 函数,否则抛出一下异常130- Textual SQL expression '***' should be explicitly declared as text('***')131'''132results = session.execute(text(sql)).fetchall();133else:134results = session.execute(text(sql));135session.commit();136session.close();137return results;138139if __name__ == '__main__':140pass - 2
- LSTM_Model.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "HymanHu";45'''6LSTM Model7'''89import math;10import numpy as np;11import pandas as pd;12from pandas import DataFrame;13from keras.models import Sequential;14from keras.layers import LSTM, Dense, Activation;15from sklearn.preprocessing import MinMaxScaler;16from sklearn.metrics import mean_squared_error;17import matplotlib.pyplot as plt;1819class LSTM_Model(object):2021'''22data:numpy 一维数组,[1 2 3...]23step_length:步长,用步长数据预测下一个数据24'''25def __init__(self, data, step_length=1):26print("构造 LSTM_Model,data 类型 %s,data 形状 %s, 步长 %s" % (type(data), data.shape, step_length));27self.data = data;28self.step_length = step_length;29self.scaler = MinMaxScaler(feature_range=(0, 1));3031self.train_data = None;32self.train_x = None;33self.train_y = None;34self.test_data = None;35self.test_x = None;36self.test_y = None;37self.predict = None;3839# 设置 numpy 数组打印格式化40np.set_printoptions(linewidth=400, threshold=6);4142# 初始化训练数据和测试数据43def init_train_test_data(self):44print("==== 初始化训练数据和测试数据 ====");45print("原始数据:%s" % self.data);4647# 将值转化为 float 类型48data = self.data.astype(float);4950# 使用 MinMaxScaler 进行数据归一化,参数需要二维结构 [[5][1][4]...[4][1][4]]51# 归一化完成后,将二维结构变回一维结构52data = self.scaler.fit_transform(data.reshape(-1, 1)).flatten();53print("归一化数据:%s" % data);5455# 数据 4/5 作为训练数据,1/5 作为测试数据56print("---- 数据拆分 ----");57train_length = int(len(data) * 0.8);58# 二维结构拆分,并返回一维结构59# train_data, test_data = data[0:train_length, :].flatten(), \60# data[train_length:len(data), :].flatten();61# 一维结构拆分62self.train_data, self.test_data = data[0:train_length], data[train_length:len(data)];63print("训练数据: %s" % self.train_data);64print("测试数据: %s" % self.test_data);6566'''67构造模型适应数据68data:numpy 一维数组 [ 5. 1. 4. ... 1. 4. 10.]69step_length:步长,用步长数据预测下一个数据701 -> 1:[[5][1][4]...[4][1][4]] ---- [ 1 4 8 ... 1 4 10]712 -> 1:[[5 1][1 4][4 8]...[4 4][4 1][1 4]] ---- [ 4 8 3 ... 1 4 10]723 -> 1:[[5 1 4][1 4 8][4 8 3]...[1 4 4][4 4 1][4 1 4]] ---- [ 8 3 12 ... 1 4 10]73'''74def build_fit_data(self, data, data_name=""):75print("==== 构造%s模型适应数据 ====" % data_name);76data_x, data_y = [], [];77for i in range(len(data) - self.step_length):78data_x.append(data[i: i + self.step_length]);79data_y.append(data[i + self.step_length]);80x, y = np.asarray(data_x), np.asarray(data_y);81# x 重构 shape (nb_samples, timesteps, input_dim)82x = x.reshape(len(x), self.step_length, 1);83# y 重构 shape84y = y.reshape(len(y), 1);85print("%s_x 数据:%s" % (data_name, x));86print("%s_y 数据:%s" % (data_name, y));87return x, y;8889'''90时间步长 LSTM 回归模型91'''92def time_step_model(self):93# 隐藏神经元94hidden_neurons = 50;95# 输入输出神经元96in_out_neurons = 1;9798print("==== 构造 Sequential 模型 ====");99model = Sequential();100'''101units:LSTM 单元内的隐藏层尺寸,理论上这个 units 的值越大, 网络越复杂, 精度更高,计算量更大;102input_shape:三维尺寸,模型需要知道它所期望的输入的尺寸,顺序模型中的第一层且只有第一层103需要接收关于其输入尺寸的信息,下面的层可以自动地推断尺寸;104input_shape=(batch_dim, time_dim, feat_dim)105input_shape=(time_dim, feat_dim)106Batch_size:比较好的方法是将 Batch_size 设置为 None107Time_step:时间序列的长度108Input_Sizes:每个时间点输入 x 的维度109activation:激活函数 relu、linear 等,也可以单独添加激活层实现 model.add(Activation("linear"));110'''111print("---- 添加 LSTM 层,该层有 %d 个隐藏神经元,relu 激活函数, 输入样本形状为 %s ----" %112(hidden_neurons, self.train_x.shape));113# model.add(LSTM(hidden_neurons, return_sequences=False,114# input_shape=(self.train_x.shape[1], self.train_x.shape[2])));115model.add(LSTM(hidden_neurons, activation='relu', input_shape=(self.train_x.shape[1], self.train_x.shape[2])));116print("---- 添加 Dense 层,该层有 %d 个输入输出神经元 ----" % (in_out_neurons,));117# 全连接层118model.add(Dense(in_out_neurons));119print("---- 编译模型 ----");120model.compile(loss="mean_squared_error", optimizer="rmsprop");121print("---- 输出摘要 ----");122model.summary();123124print("---- 使用训练数据训练模型 ----");125model.fit(self.train_x, self.train_y, epochs=10, validation_split=0.05);126print("---- 用模型对测试数据进行预测 ----");127predict = model.predict(self.test_x).reshape(len(self.test_y));128print("预测数据:%s" % (predict,));129130print("---- 数据反归一化 ----");131# 使用 MinMaxScaler 进行数据反归一化,参数需要二维结构 [[5][1][4]...[4][1][4]]132# 归一化完成后,将二维结构变回一维结构133self.predict = self.scaler.inverse_transform(predict.reshape(-1, 1)).flatten();134self.test_y = self.scaler.inverse_transform(self.test_y).flatten();135print("test_y 反归一化:%s" % (self.test_y, ));136print("预测数据反归一化:%s" % (self.predict, ));137138print("---- 计算测试数据与预测数据 RMSE 误差 ----");139# 计算均方误差回归损失140MSE = np.mean((self.predict - self.test_y) ** 2);141MSE = mean_squared_error(self.test_y, self.predict);142print('MSE:%.2f' % MSE);143score = math.sqrt(MSE);144print('Score:%.2f' % score);145146# 输出图表147def data_graph(self):148# 指定字体,可解决中文乱码问题149plt.rcParams['font.sans-serif'] = ['SimHei'];150151# '行','列','编号' ---- 2 行, 第一行列数 1, 图表编号 1152plt.subplot(2, 1, 1);153plt.plot(self.data, label="原始数据", color="black", linewidth=1);154plt.title("所有数据");155plt.xlabel("日期");156plt.ylabel("数值");157158plt.subplot(2, 1, 2);159plt.plot(self.test_y, label="原始数据", color="black", linewidth=1);160plt.plot(self.predict, label="原始数据", color="red", linewidth=1);161plt.title("测试数据 & 预测数据");162plt.xlabel("日期");163plt.ylabel("数值");164165plt.show();166167# 应用入口168def application(self):169self.init_train_test_data();170self.train_x, self.train_y = self.build_fit_data(self.train_data, "训练");171self.test_x, self.test_y = self.build_fit_data(self.test_data, "测试");172self.time_step_model();173self.data_graph();174175if __name__ == '__main__':176df = pd.read_csv("/temp/twocolorball.csv", encoding="gbk").drop(labels="Unnamed: 0", axis=1);177df = df.sort_values(by="期号", ascending=True);178data = np.asarray(df["红球1"]);179# data = np.array(list(range(1, 101)));180lstm = LSTM_Model(data=data, step_length=3);181lstm.application();182print(int(round(lstm.predict[-1]))); - 2
Entity
- Double_Color_Ball.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "HymanHu";45'''6双色球实体bean7'''89from util.sqlalchemy_util import *;1011class Double_Color_Ball(Base):1213# 指定表名14__tablename__ = "double_color_ball";1516# 创建表的参数17__table_args__ = {18"mysql_charset": "utf8"19};2021id = Column(Integer, primary_key=True, autoincrement=True, nullable=False);22issur_code = Column(String(255));23occur_date = Column(Date);24red_ball = Column(String(255));25blue_ball = Column(String(255));26recommend = Column(Text(500));27create_date = Column(DateTime);28update_date = Column(DateTime);2930if __name__ == '__main__':31init_db();32# dcb = Double_Color_Ball(33# issur_code="2023111",34# occur_date="2023-08-29 14:14:14",35# red_ball="1,2,3,6,13,31",36# blue_ball="7",37# recommend="1,2,3,14,23,33 11",38# create_date="2023-08-29 14:14:14",39# update_date="2023-08-29 14:14:14"40# )41# insert_(dcb, "issur_code");42# result = get_all(dcb);43# print(result);44# for item in result:45# print(item.__dict__); - 2
Spider
- dcb_spider.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "HymanHu";45'''6双色球爬虫7http://kaijiang.zhcw.com/zhcw/html/ssq/list.html8'''910import requests;11from bs4 import BeautifulSoup;12import re;13from entity.Double_Color_Ball import *;14from datetime import datetime;15import time;1617headers = {18"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0",19"Cookie":"Hm_lvt_692bd5f9c07d3ebd0063062fb0d7622f=1691204419; _ga_9FDP3NWFMS=GS1.1.1691204417.2.1.1691204437.0.0.0; _ga=GA1.2.812812942.1688107107; Hm_lvt_12e4883fd1649d006e3ae22a39f97330=1691204418"20}21headers_sfac={22"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0",23"Token":"eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJhdWQiOiIxIiwicm9sZSI6IkFkbWluIiwidXNlckltYWdlIjoiaHR0cDovL3d3dy5zZmFjLnh5ejo4MDAwL2ltYWdlcy9wcm9maWxlLzE2ODg3MTE5MjI0NDkuanBnIiwiaWQiOjEsImV4cCI6MTY5MzM2NzMxNiwidXNlck5hbWUiOiJhZG1pbiIsImlhdCI6MTY5MzI4MDkxNn0.ND2M1Iu19w2x0V_-TLTeBjF1jk80HQYdBAkT2fsEMeM"24}2526# 获取单页数据27def get_dcb_page_data(url):28print("单页数据:%s" % url);2930# 向目标网址发送请求,获得响应31r = requests.get(url, headers=headers);32# 根据响应状态做处理33if r.status_code == 200:34# 设置响应编码35r.encoding = r.apparent_encoding;36# 打印响应文本内容37# print(r.text);3839# 解析响应的内容40# 构造 bs 对象41bs = BeautifulSoup(markup=r.text, features="html.parser");42# 获取所有 tr 标签43tr_list = bs.find_all(name="tr");44for index, tr in enumerate(tr_list):45if index == 0 or index == 1 or index == (len(tr_list) - 1):46continue;47# print(tr);4849# 构造 DCB 对象50dcb = Double_Color_Ball(51issur_code=re.findall('<td align="center">(.*?)</td>', str(tr))[1],52occur_date=re.findall('<td align="center">(.*?)</td>', str(tr))[0],53red_ball=" ".join(re.findall('<em class="rr">(.*?)</em>', str(tr))),54blue_ball=re.findall('<em>(.*?)</em>', str(tr))[0],55create_date=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),56update_date=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),57);58# print(dcb.__dict__);59# 插入数据库60insert_(dcb, "issur_code");6162# 获取所有数据63def get_dcb_all_data(page_size=153):64# 生成链接列表65urls = list("http://kaijiang.zhcw.com/zhcw/html/ssq/list_%d.html" % page for page in range(2, page_size + 1));66urls.insert(0, "http://kaijiang.zhcw.com/zhcw/html/ssq/list.html");6768for url in urls:69get_dcb_page_data(url);70time.sleep(5);7172return True;7374# 获得 sfac 单页数据75def get_dcb_page_data_sfac(url, currentPage=1, pageSize=10):76print("单页数据:%s" % url);77search = {"currentPage":currentPage,"pageSize":pageSize,"keyword":"","sort":"issue_no","direction":"desc"};78# 向目标网址发送请求,获得响应79r = requests.post(url, json=search, headers=headers_sfac);80# 根据响应状态做处理81if r.status_code == 200:82# 设置响应编码83r.encoding = r.apparent_encoding;84print(r.json().get("total"));8586for item in r.json().get("list", []):87# 构造 DCB 对象88dcb = Double_Color_Ball(89issur_code=item.get("issueNo"),90occur_date=item.get("awardDate"),91red_ball=item.get("redBall"),92blue_ball=item.get("blueBall"),93create_date=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),94update_date=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),95);96print(dcb.__dict__);97insert_(dcb, "issur_code");9899# 获取 sfac 所有数据100def get_dcb_all_data_sfac(page_size=31):101url_sfac = "http://538b537e25.zicp.vip:13595/api/economy/bicolorSpheres";102page_size = 100;103for page in range(1, page_size + 1):104get_dcb_page_data_sfac(url_sfac, page, page_size);105time.sleep(3);106107if __name__ == '__main__':108# url = "http://kaijiang.zhcw.com/zhcw/html/ssq/list.html";109# get_dcb_page_data(url);110# get_dcb_all_data();111# url_sfac= "http://538b537e25.zicp.vip:13595/api/economy/bicolorSpheres";112# get_dcb_page_data_sfac(url_sfac);113get_dcb_all_data_sfac(); - 2
Data Process
- dcb_data_process.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "HymanHu";45'''6双色球数据处理7'''89from util.sqlalchemy_util import *;10import numpy as np;11import pandas as pd;12from pandas import Series, DataFrame;13import random;14from pyecharts.faker import Faker;15from pyecharts import options as opts;16from pyecharts.charts import Bar, Bar3D, Line, Line3D, Pie, Map, Geo, Funnel, Grid, Tab, Page;17from statsmodels.tsa.api import SimpleExpSmoothing, Holt;18from util.LSTM_Model import *;1920# 获取所有数据,构造 dateframe 对象21def build_dcb_df():22print("======== 初始化df数据 ========");23# 从数据库读取数据24sql = "select issur_code, occur_date, red_ball, blue_ball from double_color_ball order by occur_date";25result = execute_(sql);26column_list = ["期号", "开奖日期", "红球", "蓝球"];27df = DataFrame(data=result, columns=column_list);28df = pd.concat([29df[["期号", "开奖日期"]],30df["红球"].str.split(" ", expand=True).rename(31columns={0: '红球1', 1: '红球2', 2: '红球3', 3: '红球4', 4: '红球5', 5: '红球6'}),32df["蓝球"],33], axis=1);34print(df);35return df;3637# 绘制最近30期中奖号码走势图38def draw_dcb_lines(df):39print("======== 绘制走势图 ========");4041# 准备数据42occure_date = np.asarray(df["开奖日期"][-30:].apply(lambda item:str(item))).tolist();43red1 = np.asarray(df["红球1"][-30:].apply(lambda item:int(item))).tolist();44red2 = np.asarray(df["红球2"][-30:].apply(lambda item:int(item))).tolist();45red3 = np.asarray(df["红球3"][-30:].apply(lambda item:int(item))).tolist();46red4 = np.asarray(df["红球4"][-30:].apply(lambda item:int(item))).tolist();47red5 = np.asarray(df["红球5"][-30:].apply(lambda item:int(item))).tolist();48red6 = np.asarray(df["红球6"][-30:].apply(lambda item:int(item))).tolist();49blue = np.asarray(df["蓝球"][-30:].apply(lambda item:int(item))).tolist();5051Line().add_xaxis(52xaxis_data=occure_date53).add_yaxis(54series_name="红1",55y_axis=red1,56itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())57).add_yaxis(58series_name="红2",59y_axis=red2,60itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())61).add_yaxis(62series_name="红3",63y_axis=red3,64itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())65).add_yaxis(66series_name="红4",67y_axis=red4,68itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())69).add_yaxis(70series_name="红5",71y_axis=red5,72itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())73).add_yaxis(74series_name="红6",75y_axis=red6,76itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())77).add_yaxis(78series_name="蓝球",79y_axis=blue,80itemstyle_opts=opts.ItemStyleOpts(color=Faker.rand_color())81).set_global_opts(82title_opts=opts.TitleOpts(title="双色球走势图", subtitle="近30期", pos_left="10%"),83# 设置 series_name 位置84legend_opts=opts.LegendOpts(pos_left="40%"),85).render(86path="/projectCode/clazz/wish_web/static/html/dcb.html"87);8889'''90- 添加号码到号码池91- l:号码池92- nimber:号码93- is_blue:是否为蓝球94'''95def add_number_to_pool(l, number, is_blue):96max = 16 if is_blue else 33;97# 蓝球直接添加98if is_blue:99l.append(number);100return l;101elif (not is_blue) and (not l.__contains__(number)):102l.append(number);103l.sort();104return l;105else:106add_number_to_pool(l, random.randint(1, max), is_blue);107108# 随机生成双色球109def random_dcb_predict():110print("======== 随机算法预测 ========");111l = [];112for i in range(1, 8):113is_blue = False if i < 7 else True;114max = 16 if is_blue else 33;115add_number_to_pool(l, random.randint(1, max), is_blue);116print(l);117return l;118119# 平滑曲线预测120def smoothing_dcb_predict(df):121print("======== 平滑指数预测 ========");122l = [];123for i in range(1, 8):124column = "红球%d" % i if i < 7 else "蓝球";125is_blue = False if i < 7 else True;126127ses = SimpleExpSmoothing(128np.asarray(df[column].apply(lambda item:int(item)))129).fit(130smoothing_level=random.randint(1, 10) / 10,131optimized=False132);133134# 用适应模型预测数据,返回数组 [3.98919522]135result = ses.predict();136munber = int(round(result[0], 0));137# print(result, munber);138add_number_to_pool(l, munber, is_blue);139140print(l);141return l;142143# holt 预测144def holt_dcb_predict(df):145print("======== Holt预测 ========");146l = [];147for i in range(1, 8):148column = "红球%d" % i if i < 7 else "蓝球";149is_blue = False if i < 7 else True;150151holt = Holt(152np.asarray(df[column].apply(lambda item: int(item)))153).fit(154smoothing_level=random.randint(1, 10) / 10,155smoothing_trend = random.randint(1, 10) / 10,156optimized = False157);158159# 用适应模型预测数据,返回数组 [3.98919522]160result = holt.predict();161munber = int(round(result[0], 0));162add_number_to_pool(l, munber, is_blue);163164print(l);165return l;166167# lstm 预测168def lstm_dcb_predict(df):169print("======== LSTM 预测 ========");170l = [];171for i in range(1, 8):172column = "红球%d" % i if i < 7 else "蓝球";173is_blue = False if i < 7 else True;174175lstm = LSTM_Model(data=np.asarray(df[column].apply(lambda item: int(item))), step_length=3);176lstm.application();177munber = int(round(lstm.predict[-1]));178add_number_to_pool(l, munber, is_blue);179180print(l);181return l;182183def save_predict_data(result=""):184print("======== 保存预测结果 ========");185print(result);186# 查找数据库最近一条数据187query_sql = "select id from double_color_ball order by occur_date desc limit 1";188ids = execute_(query_sql);189id = 0 if len(ids) == 0 else ids[0][0];190191# 修改推荐号192update_sql = "update double_color_ball set recommend='%s' where id=%s;" % (result, id);193execute_(update_sql);194195# 调度程序196def application():197result = [];198df = build_dcb_df();199draw_dcb_lines(df);200l = random_dcb_predict();201result.append("<p>随机预测:%s</p>" % l);202l = smoothing_dcb_predict(df);203result.append("<p>平滑指数预测:%s</p>" % l);204l = holt_dcb_predict(df);205result.append("<p>Holt 预测:%s</p>" % l);206l = lstm_dcb_predict(df);207result.append("<p>LSTM 预测:%s</p>" % l);208save_predict_data("".join(result));209return "".join(result);210211if __name__ == '__main__':212# df = build_dcb_df();213# draw_dcb_lines(df);214# l = random_dcb_predict();215# print(l);216# l = smoothing_dcb_predict(df);217# print(l);218# l = holt_dcb_predict(df);219# print(l);220# l = lstm_dcb_predict(df);221# print(l);222# save_predict_data("aaaaa");223application(); - 2
Wish_Web
构建 Django 项目
- 参见 Python_Web 文档。
Models
- app_spider ---- models.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "JiangHu";45'''6- Spider 模块 models7'''89from django.db import models;1011# 注意,此处命名不能和 Wish_Spider 里面的对象命名一致12class DoubleColorBall(models.Model):13id = models.AutoField(primary_key=True);14issur_code=models.CharField(max_length=255, blank = True, null = True);15occur_date = models.DateField(blank=True, null=True);16red_ball=models.CharField(max_length=255, blank = True, null = True);17blue_ball=models.CharField(max_length=255, blank = True, null = True);18recommend=models.TextField(max_length=500, blank = True, null = True);19create_date=models.DateTimeField(auto_now=True, blank=True, null=True);20update_date=models.DateTimeField(auto_now=True, blank=True, null=True);2122# 将 class 转 dict,方便接口返回数据23def dcb_dict(self):24dcb_dict = {};25dcb_dict["id"] = self.id;26dcb_dict["issurCode"] = self.issur_code;27dcb_dict["occurDate"] = self.occur_date;28dcb_dict["redBall"] = self.red_ball;29dcb_dict["blueBall"] = self.blue_ball;30dcb_dict["recommend"] = self.recommend;31dcb_dict["createDate"] = self.create_date;32dcb_dict["updateDate"] = self.update_date;33return dcb_dict;3435# 指定表名,若不指定,默认生成表名为:app名称_类名,比如gzbd_epidemic36class Meta:37db_table = ('double_color_ball'); - 2
Common
- page_vo.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "JiangHu";45'''6- page vo 对象7'''89class Result(object):10def __init__(self, status, message, data=None):11self.status = status;12self.message = message;13self.data = data;1415def result(self):16if self.data:17return {"status": self.status, "message": self.message, "data": self.data};18else:19return {"status": self.status, "message": self.message};202122class Search_Vo(object):23def __init__(self, data):24self.current_page = data.get("currentPage", 1);25self.page_size = data.get("pageSize", 5);26self.sort = data.get("sort", "");27if self.sort == "":28self.sort = "id";29self.direction = data.get("direction", "asc");30if self.direction.lower() == "desc":31self.sort = "-" + self.sort;32self.keyword = data.get("keyword", "");3334def result(self):35search = {};36search["currentPage"] = self.current_page;37search["pageSize"] = self.page_size;38search["sort"] = self.sort;39search["direction"] = self.direction;40search["keyword"] = self.keyword;41return search;4243class Page_Info(object):44def __init__(self, total=0, current_page=1, page_size=5, list=[]):45self.total = total;46self.current_page = current_page;47self.page_size = page_size;48self.list = list;4950def result(self):51page_info_dict = {}52page_info_dict["total"] = self.total;53page_info_dict["currentPage"] = self.current_page;54page_info_dict["pageSize"] = self.page_size;55page_info_dict["list"] = self.list;56return page_info_dict; - 2
Views
- app_spider ---- views.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "JiangHu";45'''6- Spider 模块 service7'''89# 将其他项目根目录添加到 sys.path10import sys, os;11sys.path.append(r'D:\projectCode\clazz\wish_spider');1213from django.shortcuts import render, HttpResponse;14from django.http import JsonResponse;15import json;16from app_spider.models import *;17from app_common.page_vo import *;18from django.db.models import Q;19from django.core.paginator import Paginator, PageNotAnInteger, EmptyPage;20from spider.dcb_spider import *;21from data_process.dcb_data_process import *;2223# 返回字符串24def hello_world(request):25return HttpResponse("Hello World!");2627'''28- 插入 dcb | 修改 dcb29- insert_dcb | dcb | json | post | Result ----- /api/economy/dcb30- update_dcb | dcb | json | put | Result ----- /api/economy/dcb31'''32def edit_dcb(request):33if request.method == "POST":34# 获取 json 参数 dcb35dcb_dict = json.loads(request.body);36# 构造 dcb 对象37dcb = DoubleColorBall(38issur_code=dcb_dict.get("issurCode", ""),39occur_date=dcb_dict.get("occurDate", ""),40red_ball=dcb_dict.get("redBall", ""),41blue_ball=dcb_dict.get("blueBall", ""),42recommend=dcb_dict.get("recommend", ""),43);4445# 数据库查询该期数据是否已经存在46temp = DoubleColorBall.objects.filter(issur_code=dcb.issur_code).first();47if temp:48return JsonResponse(Result(500, "该期数据已经存在。").result());49else:50dcb.save();51return JsonResponse(Result(200, "插入成功。", dcb.dcb_dict()).result());52elif request.method == "PUT":53# 获取 json 参数 dcb54dcb_dict = json.loads(request.body);55# 根据 id 获取数据库 dcb 对象56dcb = DoubleColorBall.objects.get(id=dcb_dict.get("id"));57dcb.issur_code = dcb_dict.get("issurCode", "");58dcb.occur_date = dcb_dict.get("occurDate", "");59dcb.red_ball = dcb_dict.get("redBall", "");60dcb.blue_ball = dcb_dict.get("blueBall", "");61dcb.recommend = dcb_dict.get("recommend", "");6263# 数据库查询该期数据是否已经存在64temp = DoubleColorBall.objects.filter(issur_code=dcb.issur_code).first();65if temp and temp.id != dcb.id:66return JsonResponse(Result(500, "该期数据已经存在。").result());67else:68dcb.save();69return JsonResponse(Result(200, "修改成功。", dcb.dcb_dict()).result());70else:71return JsonResponse(Result(500, "不支持该请求类型。").result());7273'''74- delete dcb | get dcb75- delete_dcb_by_id | id | path | Result ---- /api/economy/dcb/176- get_dcb_by_id | id | path | dcb ------ /api/economy/dcb/177'''78def delete_get_dcb(request, id):79if request.method == "DELETE":80DoubleColorBall.objects.filter(id=id).delete();81return JsonResponse(Result(200, "删除成功。").result());82elif request.method == "GET":83dcb = DoubleColorBall.objects.filter(id=id).filter();84if dcb:85return JsonResponse(dcb.dcb_dict());86else:87return JsonResponse({});88else:89return JsonResponse(Result(500, "不支持该请求类型。").result());9091'''92- dcbs 分页查询接口93- get_dcbs_by_search | Search | json | page_info ----- /api/economy/dcbs94'''95def get_dcbs_by_search(request):96if request.method == "POST":97# 获取 json 参数 dcb98search_dict = json.loads(request.body);99search_vo = Search_Vo(search_dict);100101'''102- 根据 keyword && order by 查询所有的对象103- 多个字段模糊查询,Q(字段名1__icontains=keyword) | Q(字段名2__icontains=keyword)104- icontains、contains 区别:是否大小写敏感105'''106dcbs = DoubleColorBall.objects.filter(107Q(issur_code__icontains=search_vo.keyword) |108Q(red_ball__icontains=search_vo.keyword) |109Q(blue_ball__icontains=search_vo.keyword)110).order_by(search_vo.sort);111112# 初始化 Paginator 对象,用 Paginator 对象进行分页113paginator = Paginator(dcbs, search_vo.page_size);114try:115dcbs = paginator.page(search_vo.current_page);116except PageNotAnInteger:117search_vo.current_page = 1;118dcbs = paginator.page(1);119except EmptyPage:120search_vo.current_page = paginator.num_pages;121dcbs = paginator.page(paginator.num_pages);122123# 返回 Page_Info 的 dict124dcb_list = list(dcb.dcb_dict() for dcb in dcbs.object_list);125return JsonResponse(126Page_Info(127total=paginator.count,128current_page=search_vo.current_page,129page_size=search_vo.page_size,130list=dcb_list131).result());132else:133return JsonResponse(Result(500, "不支持该请求类型。").result());134135# 测试页面136def hello_world_page(requset):137content = {};138content["name"] = "hj";139content["age"] = 18;140return render(requset, "spider/helloWorld.html", content);141142# dcbs 页面143def get_dcbs_page(requset):144content = {};145return render(requset, "spider/dcbs.html", content);146147# 调用爬虫148def get_recent_dcbs_data(request):149if request.method == "GET":150print("==================");151result = get_dcb_all_data(page_size=1);152return JsonResponse(Result(200, "Success.", result).result());153154# 调用数据预测、图表155def get_dcb_predict(request):156if request.method == "GET":157result = application();158return JsonResponse(Result(200, "Success.", result).result());159 - 2
Urls
- urls.py
- 11
#!/usr/bin/env python32# -*- coding: utf-8 -*-3__author__ = "JiangHu";45"""6urls7"""89from django.contrib import admin;10from django.urls import path, re_path;11from app_account import views as av;12from app_common import views as cv;13from app_spider import views as sv;1415urlpatterns = [16path('admin/', admin.site.urls),17# ======== account ========18# ======== common ========19# ======== spider ========20re_path(r'^helloworld$', sv.hello_world), # 返回字符串21re_path(r'^api/spider/dcb$', sv.edit_dcb), # 返回Json22re_path(r'^api/spider/dcb/(\d+)$', sv.delete_get_dcb),# 返回Json23re_path(r'^api/spider/dcbs$', sv.get_dcbs_by_search),# 返回Json24re_path(r'^spider/helloWorld$', sv.hello_world_page),# 测试页面25re_path(r'^spider/dcbs$', sv.get_dcbs_page),# dcbs页面26re_path(r'^api/spider/recent/dcbs$', sv.get_recent_dcbs_data),# 爬取数据27re_path(r'^api/spider/dcb/predict$', sv.get_dcb_predict),# 数据预测2829] - 2
Templates
- 拆解 Bootstrap 前端模板。
效果展示